
Why Your Context Should Not Always Repeat Itself
Why Your Context Should Not Always Repeat Itself
When building memory for your team or agents, recency is often one of the strongest signals. This makes sense. In many cases, users want the most recent and relevant information.
But recency can introduce a subtle problem.
If several recent memories are all about the same restaurant, project, or person, the top results can become overly concentrated around that single entity.
For example, a query like "What dishes do I like to eat?" may return multiple memories about California Burrito simply because those memories are both recent and highly relevant.
The retrieval is technically correct, but the result set is not very representative.
Instead of seeing a broader view of preferences, the agent receives several variations of the same theme.
We wanted recency to remain important without allowing one cluster of similar memories to dominate the top-k results.
To solve this, we introduce Diversify.
Diversify uses Maximal Marginal Relevance (MMR) as a diversification step after ranking.
MMR balances relevance and similarity, helping retrieval preserve both freshness and coverage across memory.
A Real Example.
Consider the following query:
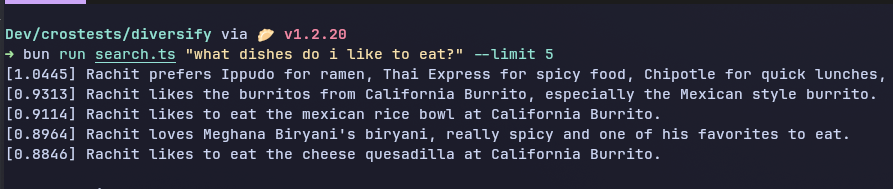
Without Diversify, the top results were heavily concentrated around California Burrito:
- Ippudo / Thai Express / Chipotle preference summary
- Burritos from California Burrito
- Mexican Rice Bowl at California Burrito
- Meghana Biryani
- Cheese Quesadilla at California Burrito
All of these results were relevant and recent, but three of the top five were about California Burrito.
With Diversify enabled:

With Diversify enabled, the results covered a broader range of preferences that is not just recency aware but diverse as well:
- Ippudo / Thai Express / Chipotle preference summary
- Cheese Quesadilla at California Burrito
- Indori Poha at Samosa Party Cafe
- Meghana Biryani
- Thai Express when craving something spicy
The results remained relevant, but provided a more representative view of the user's food preferences.
Instead of spending most of the context window on one restaurant, the agent receives a broader and more useful set of memories.
How Diversify Works
Diversify is applied after retrieval and reranking, just before the final top-k results are returned.
At this stage, we already have a set of highly relevant candidates. The goal is no longer to find relevant memories, but to avoid returning memories that are too similar to one another.
To do this, we use Maximal Marginal Relevance (MMR).
At each step, Diversify selects the next memory by balancing two signals:
- Relevance to the query.
- Similarity to memories that have already been selected.
A memory receives a lower score if it is very similar to one that is already in the result set.
This allows the strongest matches to remain, while making room for other relevant memories that add new information.
In practice, Diversify works as a lightweight post-processing step. It does not require additional LLM calls, and it preserves the original memories exactly as they were stored.
The result is a more representative set of memories without sacrificing relevance.
Using Diversify
Enabling Diversify is a single flag in the search API.
import Crosmos from "crosmos";
const client = new Crosmos();
const results = await client.search.hybrid({
query: "food preferences",
space_id: "019dc652-2724-76d6-ab4b-1b2d077019b5",
limit: 10,
rerank: true,
diversify: true, // MMR to reduce redundancy
graph: true, // include graph signal
});
Diversify is applied after retrieval and re-ranking, just before the final results are returned.
When Diversify Helps
Diversify is most useful when you want a representative view of memory rather than multiple variations of the same theme.
Common use cases include:
Exploratory Search
When users are browsing memories and want broad coverage across different topics.
Summarization
When preparing context for an agent, where redundant memories waste valuable tokens.
Pattern Discovery
When looking for trends across preferences, decisions, and experiences.
Agent Context
When agents need a balanced set of memories instead of repeated information about the same entity.
Long-Term Memory
As memory grows, clusters of similar memories become more common. Diversify helps maintain breadth without sacrificing relevance.
Final Thoughts
Relevance alone is not always enough.
When several highly relevant memories are closely related, returning all of them can narrow the context instead of expanding it.
Diversify addresses this by balancing relevance and similarity, allowing Crosmos to return a broader and more representative view of memory.
Your context should not echo itself.
Crosmos helps you provide your company and the agents you use with self-improving context and memory infrastructure so that your team is always updated and ready to start the day!
Get your API key at: https://crosmos.dev console